
[ Source code in code/filesys | Quiz ]
 Topics
Nachos
Topics
Nachos
 Networking
Networking
A file system provides the mechanism for on-line storage of and access to information belonging to the OS and its users. Here, we first discuss the file system in very general terms and then explain how it is implemented in Nachos. Note that this is not an exhaustive discussion of a file system; it is rather an overview providing information sufficient for you to understand the Nachos file system.
The logical storage unit for information is files. These are mapped by the OS into physical devices. In general, they are treated as a sequence of bits, bytes, lines or records - the meaning is defined by the file's creator. Information about all the files is kept in a directory structure that resides on secondary storage along with the files.
The interface that the OS provides for the file system comprises, among other things, of operations to manipulate files, e.g., creating, opening, writing or truncating a file. Many of these file operations involving searching the directory structure for the entry associated with the file. Since searching the file entry for each operation performed on the file can be expensive, the OS maintains a small table containing information about all open files (the open-file table). When a file operation is requested, an index into this file table is used to get the appropriate entry. When the file is no longer being used, it is closed by the process and the operating system removes its entry from the open file table.
Each process also maintains a table of all the files that it has opened. This stores information about how the file(s) are being used, e.g., the current location of the file pointer. Each entry in this table points to the corresponding entry in the open-file table.
The directories themselves may be organized in several ways, the simplest being the single-level directory. All files are contained in the same directory. The two-level directory structure allows each user to have their own directory. The tree-structured directory is a generalization of the two-level structure, containing multiple levels.
Directory Implementation The simplest method is to use a linear list of file names with pointers to the data blocks. This requires a linear search to find a particular entry. Hash tables are also used by some operating systems - a linear list stores the directory entries but a hash function based on some computation from the file name returns a pointer to the file name in the list. Thus, directory search time is greatly reduced.
In UNIX, each entry in the directory contains just a file name and its i-node number. When a file is opened, the file system takes the file name and locates its disk blocks. The i-node is read into memory and kept there until the file is closed.
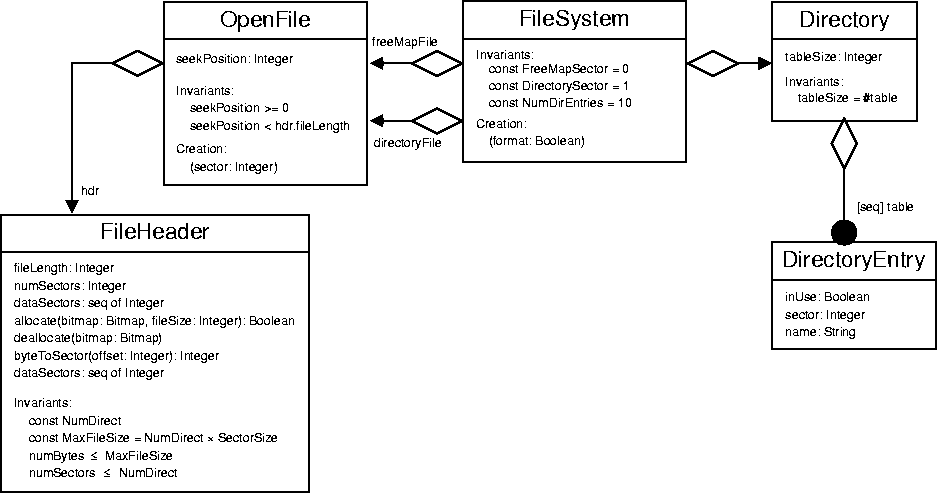
The FileHeader class (filehdr.h) is used to manage the file header (similar to an i-node in UNIX). The file header itself is used to locate where on disk the file's data is stored. The DirectoryEntry class represents a file in the directory. It contains the name of the file and where the file's header is located on disk. The Directory class defines a directory and some operations that can be performed on it, e.g., adding or removing an entry from the directory. The OpenFile class defines data structures and some routines to perform operations on open files, e.g., read, write, seek etc.
 For implementing file system calls, you can
use the routines defined in class FileSystem for opening and
creating files. These will return a pointer to an OpenFile object. For
operating on that object, e.g., reading or writing to it, you can use the
routines defined in class OpenFile.
For implementing file system calls, you can
use the routines defined in class FileSystem for opening and
creating files. These will return a pointer to an OpenFile object. For
operating on that object, e.g., reading or writing to it, you can use the
routines defined in class OpenFile.
One important thing to note in the source code is that the Nachos software comes with two versions of the file system - there is a stub version and a real version. The former just redefines the Nachos file system operations on the UNIX file system on the machine running the Nachos simulation. The reason for providing this is that the latter implementation does not provide all the functionality that a real file system does. For example, there is no synchronization for concurrent accesses to files; there is a restriction on the file size; and only a limited number of files can be added to the system. Fixing all these problems is part of a lab; this course however, does not require the lab. Since the lab on system calls and multiprogramming does require the use of a full-fledged file system, the stub version provided is used by those labs. The stub version is defined in filesys.h and openfile.h.

 Source code in code/filesys
Source code in code/filesys
Quiz
Last modified on Thursday, 29-May-97 17:03:35 EDT
